PS2000
PS2000 Der Mehrprozessor- Computer
PS-2000
Von Jurij Satuliweter und Jelena Fischcenko
Многопроцессорный компьютер ПС-2000
Юрий Затуливетер, Елена Фищенко
Übersetzung : Dr. G. Jungnickel
Zur Übersetzung-Die Übersetzung stellt eine, soweit bekannt, in der deutschen/englischen Fassung nicht verfügbare Übersicht einer SIMD - (Parallel)-Architektur dar, die in der UdSSR vorrangig für die typischen Parallelalgorithmen zur Bearbeitung geologischer Erkundungsdaten eingesetzt wurde; -Im Artikel werden russische Abkürzungen durch lateinische Buchstaben ersetzt. In (.. ) erfolgt die kyrillische Abkürzung. -In [ ] werden Bemerkungen /Erläuterungen des Übersetzers angegeben -Die Autoren Juri Satuliweter und Jelena Fischcenko (zvt\fish@ipu.rssi.ru)—sind Mitarbeiter des IPU der RAdW (Moskau |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Vorwort der Autoren
Die Postulate von John v. Neumann verbinden auch heute noch den Massencomputer und die Technologie einer industriellen Programmierung zu einem Ganzen, aber unter dieser Herrschaft der Klassik kann man künftig nur existieren, wenn man sich der Logik der seriellen Abfolge von Befehlen unterwirft, was die Vielfalt verschiedener Architektur- Lösungen und die Perspektiven des Leistungswachstums stark einschränkt |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Die Periode der „Eiszeit“ in der Architektur
1958 schlugen Jack Kilby und Robert Noyce unabhängig voneinander erstmals in der Welt integrierte Schaltungen vor. Kilby erhielt im Jahre 2000 den Physik- Nobelpreis und Noyce wurde einer der Mitbegründer der Firma Intel im Jahre 1968. Beide stehen heute in der Liste der Menschen, die die Welt veränderten, auf dem 5. Rang. www.liverating.ru/n_id/1861. ) Dieses Ereignis löste neben anderen Ereignissen den Start in das Zeitalter des massenhaften Computerbaus aus. Die Senkung der Kosten wurde eine Grundbedingung nicht nur für Computer mit Massenanwendung, auch die Entwickler von Supercomputern gingen im Interesse der Ökonomie von Kosten und Zeit auf die „Großblock- Bauweise“ von Mehrprozessor-Computern über. Die typisierte Bauelemente- Basis spielte allerdings mit den Entwicklern von unikalen [einzigartigen] Architekturen, die entsprechend arbeitsaufwendiger sind, ein böses Spiel: die Leistungsparameter von Supercomputern wurden nicht etwa durch Verbesserung der Qualität ihrer Architektur und ihrer Schaltkreislösungen, verbessert, sondern durch einfachen Tausch der Generation ihrer Mikroprozessoren [und sicher auch ihrer Anzahl in den Clustern]. Jede neue Generation engte aber die Möglichkeit der Architekten ein, auf Qualitätsparameter Einfluss zu nehmen. Zunächst verhinderte die Moder der „Großblock- Bauweise“, dass die Entwickler [von unikalen Architekturen] Zugang zu Arithmetik-Operationen auf Registerniveau für den programmierten Zugriff auf Zwischenergebnisse haben. Aber genau da wird bekanntlich die massive Parallelität bei der Ausführung von arithmetisch- logischen Befehlen ermöglicht. Möglichkeiten für das Schöpfertum der Architekten blieben im Bereich der Kommunikation zwischen den Prozessoren auf den Niveau des Hauptspeichers , was langsamer, als auf Registerniveau ist, und im Konstruktionsbereich: Schrank, Logik- Platinen, Kühlung. Langsam engten sich die Vollmachten der Architekten noch stärker ein: beeinflussbar blieben hauptsächlich verhältnismäßig langsam zusammenwirkende Prozesse. Das Potential für Parallelität auf diesem Niveau ist nicht hoch und lässt sich schlecht nutzen wegen der Besonderheit der Logik asynchroner Wechselwirkungen. Mit der Zeit wurden auch die Verbindungsblöcke [Kommunikations- Blöcke] , die zuvor noch aus Einzelelementen gebaut wurden , durch Serienkomponenten zur Unterstützung von Netzprotokollen ersetzt. Im Ergebnis „evolutionierten“ Mehrprozessor- Architekturen zu Clustersystemen. Der Kampf um die Kostensenkung und um die Termine des Baus von [eigenen] Großplatinen führte schließlich zum Kauf von fertigen Computerblöcken mit großen Steckverbindern und von Netzkomponenten. Die Notwendigkeit tiefgehender Architektur- Entwicklungen auf dem Niveau kleiner Bausteine entfiel. Das Moor’sche Gesetz [siehe http://de.wikipedia.org/wiki/Moorsches_Gesetz] eröffnete die Epoche der Mikroprozessoren. Dieses Gesetz beendet sie auch , indem es für Milliarden von Transistoren eine vollständige Freiheit der Architektur- Formen mit unbegrenzter Parallelität erfordert. Das klassische Modell der seriellen Berechnung verliert seinen Status als systembildender Standard, mit dessen Hilfe bislang die Massenfertigung von Computern und die industrielle Softwareentwicklung verknüpft waren. Heute existiert nicht einmal eine allgemein anerkanntes Verständnis darüber, wie man die industrielle Technologie der Programmierung der Vielfalt der Parallel-Computer- Architekturen aufbauen sollte. Hochparallele Mehrprozessor- Architekturen mit einem für den Programmierer zugängigen Parallelitäts- Niveau kommen jetzt wieder. Die Eiszeit des Vergessens solcher Architekten, die gleichzeitig auf allen Niveaus der gerätetechnischen Parallelität arbeiteten – von der Architektur bis zum Transistor- ist beendet. Allerdings stehen zwei prinzipielle Hürden auf dem Wege zu grenzenlos effektiven Architektur- Lösungen , die um Größenordnungen sowohl die Performance, als auch die Performance- Effektivität pro eingesetztem Gatter übersteigen, die man wie folgt formulieren kann:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Innovativer Durchbruch
In der UdSSR wurde in den 70ger Jahren die Schaffung von hochproduktiven Rechnersystemen für die Bearbeitung großer Datenmengen eine erstrangig wichtige staatliche Aufgabe. Nur für die industrielle Bearbeitung der im Lande gesammelten seismologischen Daten von Lagerstätten von Öl und Gas war eine Gesamt-Rechenleistung von ca. 100 Mrd. Additionsbefehlen / sec. erforderlich, was ca. 1000 mal die Rechenkapazität aller im Lande verfügbaren EDVA übertraf. Noch leistungsfähigere Systeme waren erforderlich, um in Echtzeit die akustischen, Radar- und Grafik- Informationen zu verarbeiten, die mittels Erd-Satelliten erhalten wurden. Es war absolut klar, dass es unmöglich war, die Rechen-Leistung nur durch die Erhöhung der Zahl der Rechner aus Serien- Produktion zu erhalten. In den Jahren 1972–1975 wurde im Moskauer Institut für Steuerungs- Probleme( IPU) die Struktur und Architektur des Hochleistungs- Mehrprozessor- Rechners PS-2000 (ПС-2000) vorgeschlagen, deren Autoren es gelang, eine originelle Lösung zu finden , die hohe Rechen-Performance vereinte mit der damals verfügbaren preisgünstigen und zuverlässigen , aber langsamen Bauelementebasis. Auf Anordnung des Ministeriums für Gerätebau wurde dem IPU als Projektverantwortlichem das NII UWM (НИИ УВМ) [Forschungsinstitut für Steuerrechner] zugeordnet, welches zur NPO „Impuls“ («Импульс») (Severodonezk) gehörte und wo die in Serie produzierten Kleinrechner des SKR „СМ-1“ und „СМ-2“ entwickelt und produziert wurden. 1975 wurde ein gemeinsames Forschungs- und Produktionsprojekt gestartet und finanziert. 1978 wurde der Führung des Landes ein vollfunktionsfähiges Muster des PS-2000 vorgestellt, und im Dezember 1980 wurden einer staatlichen Prüfungskommission die Serienmaschinen des Rechnerkomplexes PS-2000 vorgestellt. Im Folgejahr begann die Serienproduktion. Von 1981 bis 1988 wurden vom Severodonezker Werk 180 Rechnerkomplexe PS-2000 gefertigt, darunter 242 Mehrprozessor- Computer PS-2000. Die effektive Leistung der Serienanlagen PS-2000 erreichte 200 Mio. Additionen/ sec. bei sehr günstigen Kostenparametern für Anschaffung und Betrieb. Unter Feldbedingungen von geologischen Expeditionen bearbeitete PS-2000 die Ergebnisse von seismologischen Untersuchungen mindesten 20 Stunden h/Tag. Die einheimische Industrie produzierte weltweit erstmals in großen Stückzahlen einen Hochleistungs- Mehrprozessor- Rechner. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
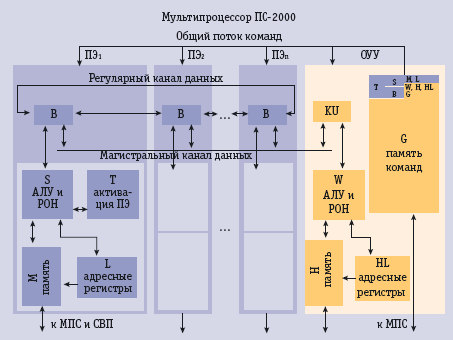
Die Architektur des PS -2000Der Mehrprozessor- Rechner ( Multiprozessor) PS-2000 ist für Aufgaben vorgesehen, die über Massiv- Parallelität auf dem Niveau der Elementar- Befehle verfügen und auf eine Hochleistungs- Verarbeitung von Daten mit gut parallelisierbaren Algorithmen orientiert sind. Die synchrone hochparallele Verarbeitung vieler Datenströme im Computer erfolgt unter Steuerung eines gemeinsamen Operationen [ Instruktions-] -Stromes, wie das für SIMD- Architekturen ( ein Instruktions- Strom, viele Daten- Ströme) typisch ist. Der Multiprozessor besteht aus einer Menge von gleichartigen Prozessor- Elementen PE1,.. PEn (ПЭ1, ПЭ2, …, ПЭN), die untereinander durch einen regulären und Magistralen- Kanal [Bus] verbunden sind und aus einer gemeinsamen Steuereinheit (OUU;ОУУ) ( Bild 1; рис. 1).
Jedes PE, wie auch die OUU, besteht aus mehreren Funktionsblöcken ( siehe PE1/ Bild 1), die auch die schnellsten im Rechner genutzten Registerspeicher enthalten, die auf Instruktions- Niveau zugängig sind. Die Gesamtheit dieser Einheiten ( sowohl der OUU , als auch sämtlicher PE ) bildet ein verzweigtes Pipeline- Aggregat mit programmtechnisch konfigurierbaren [steuerbaren ] Verbindungen. Jeder Funktionsblock stellt eine Pipeline- Stufe dar. Der Datenaustausch zwischen diesen Blöcken erfolgt über ein gemeinsam für die benachbarten Blöcke vorhandenes Register. Die Tabelle 1 [табл. 1.] zeigt Umfang und Funktionalität jeder PE .
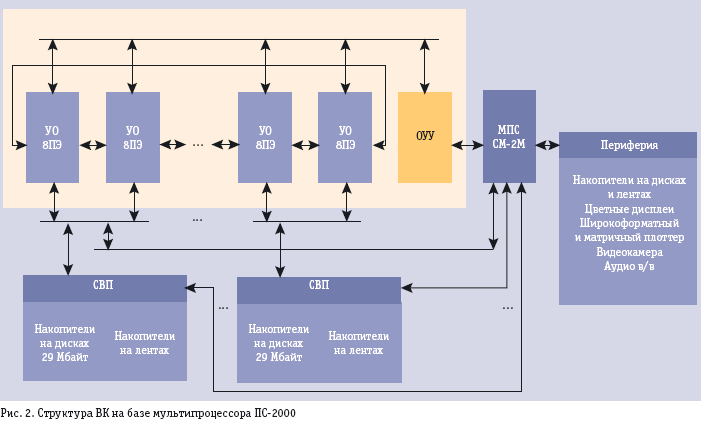
Die OUU gewährleistet die Eingabe und Speicherung des Multiprozessor- Programms , die Generierung und Übertragung aller gemeinsamen Steuersignale für alle PE, die Synchronisierung der Verarbeitungsprozesse und der Ausgabe/ Eingabe , den Testbetrieb der PE , sowie die Verbindung mit dem externen Monitoring- Subsystem (MPS) (МПС)- gem. Bild 2 (рис. 2). Die Tabelle 2 [табл. 2.] zeigt Umfang und Funktionalität der OUU
Die originelle Architektur des PS-2000 vereinte die verhältnismäßig einfache gerätetechnische Lösung der Steuersysteme für einen Instruktions- Strom mit einer beispiellos flexiblen Programmierung der hochparallelen Verarbeitung von Daten. Die unikale Flexibilität der Steuerungssystems des PS-2000 bricht mit der allgemein verbreiteten Vorstellung über die funktionellen Möglichkeiten von SIMD- Computern. Es ist zwar unglaublich, aber trotzdem wurde in den Serienmaschinen PS-2000 etwas Undenkbares für diese Klasse von Rechnern realisiert. Mit den Ressourcen des PS-2000 wurde auf Programmniveau eine Multiprozessor- Architektur MIMD ( viele Instruktions- Ströme, viele Daten- Ströme) emuliert. Dabei konnten alle PE , unter paralleler Steuerung der Aktivierungseinheit , gleichzeitig ihr eigenes Programm ausführen, welches in ihrem eigenen Operativspeichermodul geladen war. So konnte z.B. der 64- Prozessor- PS-2000 parallel 64 verschiedene Programmströme abarbeiten. Andere existente SIMD- Computer konnten das damals nicht. Es sollen daher die Architektur- Besonderheiten des PS-2000 aufgeführt werden, die ihm diese hohe Flexibilität und Effektivität der Berechnung ermöglichten:
Das Befehls- (Instruktions-) SystemDie Programmierung des Multiprozessors erfolgt mittels hochparalleler hierarchisch strukturierter Instruktionen , die dem Programmierer eine anschauliche Darstellung der Parallelität der funktionellen Einheiten und eine hocheffektive Steuerung aller Aktionen erlauben, die synchron im verzweigten Pipeline- Aggregat ausgeführt werden und die Funktions- Einheiten PE und OUU verbinden.
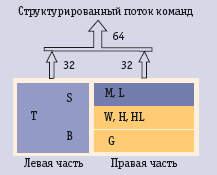
Die zwei oberen Ebenen der Befehlsstruktur sind in Bild 3 dargestellt. Alle Befehle haben ein einheitliches Format von 64 Bit und sind auf zwei zwei gleiche Teile- links und rechts aufgeteilt. Jeder Teil enthält mehrere Felder. In jedem Feld wird für die entsprechende Funktionseinheit eine Menge von drei- Adress- Befehlen für Operationen mit den Registern angegeben. In den linken Feldern wird die Steuerung von T und entweder S oder T vorgenommen . Im rechten Teil erfolgt die Steuerung entweder von M und L oder von W, H und HL oder von G. Nach einer einfachen Dekodierung des Befehls werden alle in den Feldern angewiesenen Aktionen parallel und synchron in den entsprechenden Funktionseinheiten durchgeführt. Je mehr Aktionen in den Feldern jedes Befehles angegeben sind, um so höher ist die Parallelität des Programms, die Effektivität der Nutzung der Rechenressourcen und natürlich der Ausführungsgeschwindigkeit. Die Kunst des Programmierens des Multiprozessors besteht darin, Programme zu schreiben, die ein Maximum an ausgeführten Aktionen in den Befehlsfeldern haben. Die Effektivität der ParallelisieErung wird erhöht mittels der zeitlichen Zusammenfassung von verschiedenartigen Funktionsblöcken. Zum Beispiel, die Ausführung von massiv großen Rechnungen in den Funktionsblöcken S PE wird zusammengelegt mit begleitenden Operationen ( Vorbereitung der Einstellungen, Modifikation der Adress-Operanden, Auslesen der Operanden, Speichern der Ergebnisse, Steuerung der Konfiguration des Lösungsfeldes u.s.w. ) Auf diese Weise nutzt der Multiprozessor PS-2000 mit gemeinsamen Befehlsstrom maximal die Parallelität der verschiedenartigen und gleichartigen Funktionsblöcke.
Konfigurationsvarianten ( Erweiterbarkeit, Kaskadierung)Der Multiprozessor PS-2000 wird aus Moduln drei verschiedener Typen konfiguriert, wovon jeder jeweils in einem Schrank [Schrankgehäuse] untergebracht ist. Die Erweiterungs- Moduln [d.h. Erweiterung durch Aneinanderreihung, Kaskadierung ]- werden bestückt mit Verarbeitungs- Einheiten (UO), die jeweils aus 8 PE und einer OUU bestehen. Die Moduln haben folgende Inhalte:
Die Minimalkonfiguration (8 PE )besteht aus einem Schrank , die maximale (64 PE) besteht aus 5 Schränken, aufgestellt in Form eines Sternes . |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Technische Eigenschaften der Geräte des PS-2000Die Geschwindigkeit, die Verarbeitungsbreite und die Größe der Registerspeicher und Operativspeicher wurden von der verfügbaren Bauelementebasis bestimmt, allerdings hängen Struktur und Architektur nicht wesentlich von der Bauelemente- Basis ab. Das Gerät S arbeitet mit 24-bit Register- Operanden. Eintakt- Arithmetik- Befehle mit Festkomma werden mit den Worten innerhalb von 0,32 µs ausgeführt, das entspricht einer Arbeitsfrequenz von 3 MHz. Addition/ Subtraktion im Gleitkommaformat werden innerhalb von 3 Takten ausgeführt (0,96 µs), die Multiplikation in 5 Takten ( 1,6 µs). Das Volumen eines Datenspeichermoduls M oder H betrug 16384 [15 Bit ="100000000000000" ] 24- Bit Worte , die Lese - oder Schreibbefehle wurden wordweise innerhalb von 0,96 µs ausgeführt. Das Volumen des Programmspeichermoduls G betrug 16384 64-Bit Worte. Die Auslesezeit jedes Befehls betrug 0,32 µs, die Zeit für Verzweigungsbefehle betrug von 1,28 bis 1,92 µs. Der reguläre Kanal gewährleistete einen Datenaustausch im Modus des segmentierten zyklischen Verschiebens zwischen benachbarten PE. In 0,32 µs erfolgten Übergabe und Empfang von N 24- Bit Worten, wobei N die Zahl der PE im Multiprozessor PS-2000 ist. Der Magistralen- Kanal ggewährleistet eine "öffentliche" Übertragung von einem 24 Bit Wort an alle aktiven PE entweder aus dem Register KU OUU in einem Takt in 0,32 µs , oder aus einem beliebigen PE in zwei Takten (0,64 µs). Der reguläre und der Magistralen- Kanal können programmtechnisch segmentiert werden in mehrere untereinander nicht verknüpfte gleich große Fragmente von 8, 16, 32 oder 64 PE. Bei einer Taktfrequenz von 3 MHz war die mittlere Produktivität eines 64 Prozessor- Computers PS 2000 bei Aufgaben zur industriellen Bearbeitung von Daten nahe an der Spitzenleistung von 200 MFLOPS. Rechnerkomplexe auf Basis von PS-2000Zum Rechnerkomplex (RK) PS-2000 (s.oben Bild 2 ; рис. 2) gehören der Multiprozessor, das Monitor- Untersystem und zwischen 1 bis 4 Untersysteme für Externspeicher SEPs , die eine parallel-asynchrone Arbeit mehrerer E/A-Kanäle im Modus der gleichzeitigen Arbeit vieler Informations- Magnetdatenspeicher ( auf Platte oder Magnetband) unterstützen. Bei Arbeit mit physischen Objekten im Echtzeitbetrieb kann man an den Multiprozessor mehrkanalige asynchrone Informationsströme ankoppeln , sowohl über das SEPs, als auch über spezielle Hochgeschwindigkeits- Kanäle. Das Monitoring- Subsystem auf Basis des Minirechners СМ-2М realisiert die Funktionen des Betriebssystems, realisiert die asynchrone Arbeit mehrerer SESp , die Übertragung , die Bearbeitung von Texten, die Ausführung von Hilfsprogrammen , die Steuerung der eigenen Peripherie , incl. des externen Speichers, sowie verschiedener E/A- Geräte.
Besonderheiten der ProgrammierungDie Haupt- Programmiersprache des Multiprozessors war der Microcode PS-2000. Die Möglichkeiten der Programmierung der Konfiguration ermöglichten die Schaffung von industriellen Anwendungen, die invariant waren gegenüber unterschiedlichen Konfigurationen des Multiprozessors PS-2000. Diese Eigenschaften sicherten seine Popularität , obwohl die Schaffung von parallelen Programmen für den PS-2000 eine besondere Kunstfertigkeit erforderte. Oft beeindruckte die erreichte Effektivität des Ressourceneinsatzes die Entwickler selbst- die Rechenzeit verkürzte sich um das viele hundert- fache. Die erhöhte Mobilisierung der schöpferischen Kräfte des Programmierers, die die hochparallele Maschinenstruktur erforderte, wurde in der Regel durch die professionelle Genugtuung über das Erreichte kompensiert. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Anwendungsbereich des PS -2000Die breiteste Anwendung erfuhr der Rechnerkomplex PS-2000 in der Geophysik- die schnell wachsenden Regale mit Magnetbändern mit Daten aus der Geophysik, die über Jahre stumm die Geheimnisse über Gas- und Öllagerstätten bewahrten, bestimmten den Erfolg voraus. Schon in den 70er Jahren konnte die seismologische Erkundung so erfolgreich kilometergroße Tiefen der Erde "durchleuchten" und die Daten dazu speichern, dass die Magnetbandarchive der Rechenzentren buchstäblich den Leuten auf den Kopf fielen. Allerdings konnte man pro Jahr nur wenige Prozente dessen entschlüsseln, was von einer Erkundungssaison eintraf. Für die Verarbeitung seismologischer Erkundungs- Daten von Öl und Gas wurde im VNII Geophysik (ВНИИ Геофизики) unter Mitwirkung des IPU RAdW (ИПУ РАН) das System zur industriellen Bearbeitung von geophysikalischer Information - SOS-PS (СОС-ПС) geschaffen. Im Industriebereich wurden fast 90 geophysikalische [mobile] Expeditions- Rechnerkomplexe PS- 2000 ( EGWK PS-2000;ЭГВК ПС-2000 ) betrieben, die eine vertiefte Bearbeitung der Seismo- Daten für Öl- und Gaserkundung ermöglichten. Der EGWK PS-2000 wurde gemäß den Anforderungen [Aufgabenstellung] des Ministeriums für Geologie geschaffen und war der einzige im Lande existierende problemorientierte Rechnerkomplex, der mit allen Geräten ausgerüstet war, die zur Bearbeitung von Erkundungsdaten benötigt wurden. Der EGWK PS-2000 benötigte keine große Aufstellfläche, hatte für damalige Zeiten relativ wenig Energiebedarf , geringe Betriebskosten und gewährleistete eine hohe Zuverlässigkeit unter Expeditionsbedingungen. Der Einsatz des EGWK PS-2000 erlaubte es , auf den Import teurer ausländischer Rechnerkomplexe zu verzichten. Der bestätigte ökonomische Effekt des Einsatzes des EGWK PS-2000 nur in der Geophysik betrug ca. 200 Mio Rubel , für seine Entwicklung wurden ca. 10 Mio. Rubel eingesetzt.[ zum Vergleich: 1975 betrug das Durchschnittseinkommen eines Industrie- Ingenieurs in der UdSSR ca. 150-180 Rubel/Monat]. Auf der Basis mehrerer Komplexe PS-2000 wurden Hochleistungssysteme ( bis zu 1 Mrd. OP/s.) für die Bearbeitung von hydroakustischen und telemetrischen Informationen im Echtzeitbetrieb eingesetzt. Mehrere Multiprozessoren PS-2000 wurden zu einer Pipeline verbunden. Um eine schnelle Ein- und Ausgabe der hydroakustischen und Satelliten- Informationen zu ermöglichen, wurden für solche Systeme Hochgeschwindigkeits- Kanäle realisiert. Der RK PS-2000 wurde lange Zeit im Leitzentrum für kosmische Flüge (ZUP; ЦУП) eingesetzt. Die ersten Rechner- Komplexe (RK) PS-2000 kamen 1982 ins ZUP, die letzten 1988. Insgesamt waren acht 32-Prozessor-Komplexe im Einsatz. Die RK PS- 2000 zur Satelliten- Informationsauswertung wurden von 1986 bis 1997 genutzt, als SYstem zur Vorverarbeitung der telemetrischen Daten. Die RK wurden auch für die Betriebsführung der Orbitalstationen "MIR" «Мир» eingesetzt. Die hohe Parallelität des PS-2000 ermöglichte neuartige Verarbeitungsalgorithmen für Satelliten-Daten zu nutzen. An ein zentrales System "Elbrus 2" («Эльбрус-2») waren einige 32- Prozessor-RK PS-2000 angeschlossen , um acht vollständige Telemetrie- Datenströme zu bearbeiten. Um die Zuverlässigkeit zu erhöhen, arbeiteten zwei Telemetrie- Komplexe parallel und auf den dynamischen Teilen der Flugbahn der kosmischen Objekte - drei. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Resümee Mit Erscheinen von Multi- Core Chips wird die Nachfrage nach modernsten Mikroprozessor- Architekturen verstärkt, welche balanciert sind hinsichtlich einer Einchip- Realisierung. Daher ist die Aufgabe der Umsetzung der PS-2000-Architektur auf einem Chip höchst aktuell. Die bezgl. der Anzahl der Prozessorelemente erweiterbare Architektur des PS-2000 ermöglicht es, die Zahl der Elemente proportional zur Zahl der auf einem Chip platzierbaren Gates [Transistoren] zu erhöhen. Eine Rechenleistung nahe an 1 TFLOPS kann mit 512 Elementen auf einem Chip erreicht werden (zvt.hotbox.ru/PS-2000M.htm). Siehe auch Abschnitt Mikroarchitektur PS-2000M Der Abbruch der Finanzierung der wissenschaftlichen Entwicklungen Mitte der 90er stoppte die Entwicklung der Architektur- Linie PS-2000. Es besteht jedoch eine Hoffnung, dass im Verlaufe der letzten 15 Jahre kein [unaufholbarer] Rückstand eingetreten ist, dass im Ausland die Entwicklung der Architektur von Hochleistungssystemen genau in diese [µProzessor beeinflusste ] "Eiszeit" fiel. Unser Zusammenbruch und deren Stagnation fielen diesmal zusammen. Jetzt, im Umfeld der Krise des klassischen Modells der seriellen Rechnung [nach von Neumann] und des empfindlichen Hungers nach Mehrprozessor- Einchip - Architekturen gibt das System PS-2000 seine gewichtige Antwort auf die Frage « Was ist wichtiger- die Bauelemente- Basis [Technologie- Basis] oder die Architektur?» Ein Computer mit besserer Architektur kann seine Vorzüge auch mit einer schlechten Technologie- Basis beweisen, aber mit einer hochmodernen Technologie- Basis wird er seines Gleichen suche. 30.11.2007г |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Die Multicore- Zukunft der Multiprozessorarchitektur PS-2000- |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Nachfolgend soll eine Ergänzung dieses Themas durch einen Auszug aus einem Artikel der gleichen Autoren -Ю.С. Затуливетер; Институт проблем управления им. В.А. Трапезникова РАНРоссия, 117997, Москва, Профсоюзная ул. 65 ;Е-mail: zvt@ipu.rssi.ru -Е.А. Фищенко; Институт проблем управления им. В.А. Трапезникова РАНРоссия, 117997, Москва, Профсоюзная ул.,Е-mail: fish@ipu.rssi.ru aus den "Proceedings of the third international conference "Parallel computations and control problems"; Moscow, 02.-04.10.2004" erfolgen.
Die ihrer Bedeutung nach fundamentalen Architektur- Lösungen des Multiprozessor Rechnersystems PS 2000 sind nicht an eine Bauelementebasis gebunden. Sie eröffnen qualitativ neue Möglichkeiten für eine effektive Umsetzung einer hochparallelen SIMD- Architektur universeller Zweckbestimmung in VLSI- Elemente, wobei sie eine Parallelisierung sowohl auf dem Niveau von Massen- Befehlen, als auch auf der Ebene paralleler, gegenseitig zusammenwirkender Prozesse bieten. Wie bekannt sind Multiprozessorsysteme mit SIMD- Architekturaußerordentlich effektiv für die Verarbeitung von Multimedia- Daten [23, 24] als auch zur digitalen Signalverarbeitung [25], zur Bearbeitung wissenschaftlicher Aufgaben , welche sich gut mittels paralleler Algorithmen beschreiben lassen, zur Bearbeitung akustischer, Radar- und Telemetrie- Daten. In diesem Zusammenhang stellt sich die Schaffung eines universellen programmierbaren Multiprozessors mit SIMD - Architektur auf einem Chip als höchst aktuelle Aufgabe, der auf vielen Gebieten die verschiedensten spezialisierten Beschleuniger ersetzen könnte. Die Mikroarchitektur PS-2000M , d.h. die Architektur des Multiprozessors PS-2000, die für die Realisierung auf einem Chip vorgesehen ist, ist äußerst effektiv für die Lösung von Aufgaben, bei denen mit einem Eingabe-Datensatz viele Zwischenaktionen durchzuführen sind. Die Forderungen an die Balance [Gleichgewicht] der Mikroarchitektur sind [2]:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
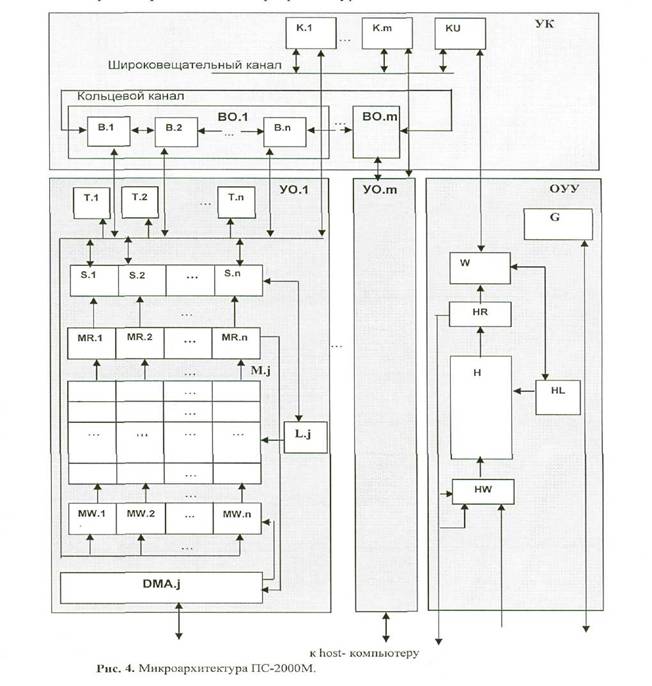
Auf
Bild 4 ( рис.
4 ) ist die Mikroarchitektur des Multiprozessors PS-2000M
dargestellt.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Sie
enthält eine gemeinsame Steuereinheit (OUU; ОУУ) , m
Verarbeitungseinheiten( UO; УО) und eine
Kommunikationseinheit (UK; (УК). Jede UO.j , mit
j
Die Steuereinheit OUU enthält : H - Speicherbank mit freiem Zugriff, HW - Eingangspuffer der Speicherbank H , HR - der Ausgangspuffer der Speicherbank H, HL — die Adresseinrichtung zur Speicherbank, HW HW - eine Arithmetik/ Logikeinheit mit universellen Registern, und O- der Befehlsspeicher. - Die Kommunikationseinheit UK (УК) enthält den "öffentlichen " Kanal und den Ringkanal . Der öffentliche Kanal enthält m Register K.j und das Register KU. K.j ist mit UO,j verbunden und KU mit der OUU . Der öffentliche Kanal ist für die Übertragung gemeinsamer Dateien an alle PE zuständig, entweder aus dem OUU, oder aus einer . beliebigen aktivierten PE. Der Ringkanal besteht aus m Ringen BO.j . Jeder Ring BO.j besteht aus n- Registern B.1, B.2 ,... B,n . Der Eingang jeder Einheit Bl ist mit den Registern МR.i, Т.i, L.j und К.j. verbunden , sein Ausgang mit MW.i, В.i,L.j und K.j. Die Auswahl der PE,i die sich mit dem für alle gleichen PE verbindet , die zum UO führen, zu den Registern L.j und K.j erfolgt mittels der Aktivierungs- Einheit T.i.. In Bild 5 ist die Befehlsstruktur bezeigt, die aus Feldern besteht , die die gleichzeitige Arbeit der Vektor-bearbeitenden Funktionselemente Т, S, М oder L, DМА, des Ringes oder der Magistralen- Kanäle К der Skalare- bearbeitenden Funktionseinheiten Н oder HL, W,G. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Gegenwärtig begrenzt die Durchsatzleistung der Speicher wesentlich die Effektivität von Multicore Rechnersystemen. In der Mikroarchitektur PS-2000M erhöht sich die Durchsatzleistung des Speichers V wesentlich, da sie proportional zu allen Hauptparametern ist , die die Parallelität und die Geschwindigkeit der Architektur bestimmen :
wobei t - die Zahl der lokalen Banken des dynamischen Speichers М.j in t Verarbeitungseinheiten ist, p- die Zahl der Worte in der Zeile der Speicherbank M.j, r - die Bitlänge des Wortes, f- die interne Taktfrequenz des Speichers im Chip . Die Durchsatzleistung des Speichers wächst wesentlich, sowohl dank der deutlichen Erhöhung der Zahl der gleichzeitig gelesenen Informations- Bit, als auch dank der Erhöhung der Taktfrequenz des Speichers. So beträgt für t=64, p=8, r=32, f=1000 Mhz die Durchsatzleistung 160 ТBit/s. Die Zugriffszeit zum dynamischen Speicher wird konstant dank der Adressierung nur der Zeilen der Speicherbank und ermöglicht eine synchrone Arbeitsweise. Es ist leicht zu sehen, dass die funktionellen Möglichkeiten des programmtechnisch gesteuerten Speichers in der PS-2K - Architektur, das auf einem Chip sitzt, um ein Vielfaches die Möglichkeiten eines Buffer- Cache- Speichers übersteigen, welcher auf dem Chip des Mikroprozessors, auch bei Multicore - Prozessoren, sitzt. Die Erweiterung durch Aneinanderreihung [Kaskadierung] des Multiprozessors PS-2000M wird gewährleistet durch die Möglichkeit der programmierten Konfigurierung der Ring- und der "öffentlichen" Kanäle, was übrigens auch die Möglichkeit bietet, auch einzelne Verarbeitungseinheiten abzuschalten und dadurch den Grad der Ausbeute der Chips zu erhöhen. Die der Multiprozessor- Architektur PS-2000 zugrunde gelegten Architektur- Prinzipien sind heute besonders aktuell. Damals erlaubten sie bei einer für heutige Verhältnisse sehr geringen Taktfrequenz von 3 МHz von einer Struktur mit 64 parallel arbeitenden PE des PS-2000 eine Spitzenleistung von 200 МIPS (oder 50 МFLOPS ), was sich durch Multiplikation der Taktfrequenz mit der Zahl der parallelen PE ergibt. Dabei arbeitete der Verbund aus 64 langsamen (3 MHz) PE wie ein kompakter "superschneller" Prozessor mit einer Frequenz von 200 MHz. Es wäre hinzuzufügen, dass die nahe 100% betragende mittlere Auslastung aller PE unter realen Anwendungen eine mittlere Leistung ermöglichte, die nahe an der Spitzenleistung lag, was bei den wichtigsten Industrie-Aufgaben der Datenverarbeitung der Fall war. Gegenwärtig könnte die Realisierung der Mikroarchitektur des PS-2000M in einem Chip mit einer Taktfrequenz von 2 GHz eine Leistung von mehr als 120 GIPS bringen, oder umgerechnet einen Prozessor mit einer Frequenz von 120 GHz. Die Existenz einer großen Reserve an Gates die heute auf Mikroelektronik-Chips möglich ist, gibt die Möglichkeit, die Produktivität der Arithmetik- Befehle mit Gleitkommaformat deutlich zu erhöhen, was es erlaubt, die Produktivität eines einzelnen Chips mit 64 PE mit ca. 120 GFLOPS abzuschätzen. Die Erweiterbarkeit [Kaskadierung] der Architektur hinsichtlich der Zahl der PE in der PS-2000 Architektur ist proportional dem Zuwachs von Gates auf dem Chip. Mit den angegebenen Annahmen kann die Leistung die Größe von ca. 1 TFLOPS bei 512 PE auf einem Chip erreichen. Eine Bauelementebasis aus Multicor- Chips mit PS-2000 Architektur eröffnet die Möglichkeit der Schaffung von programmtechnisch rekonfigurierbaren Parallel- Pipeline- Systemen mit superhoher Leistung sowohl für speziellen Bedarf, als auch für allgemeine Anwendung. Mit derartigen Chips kann man eine Leistung von 1 PFLOPS in wenigen Schränken erreichen. Der Einsatz von dynamischen Speichern ermöglicht den Energieverbrauch auf einem PS-2000M -Chip zu senken. Der Einsatz einer massiv- parallelen kaskadierbaren SIMD- Architektur für die Organisation der Rechenoperationen und eines verteilten Speichers ermöglicht es , durch Änderung der internen Taktfrequenz den Quotienten aus Rechnen- Leistung und Energieverbrauch zu regulieren, aber auch mittels eines Gleichgewichtes [ Balance] zwischen der Apparatur für Rechenoperationen und Speicher. Das macht die PS-2000M-Architektur leicht anpassbar bzgl. des Energieverbrauch und ermöglicht deren Einsatz in mobilen Geräten. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||